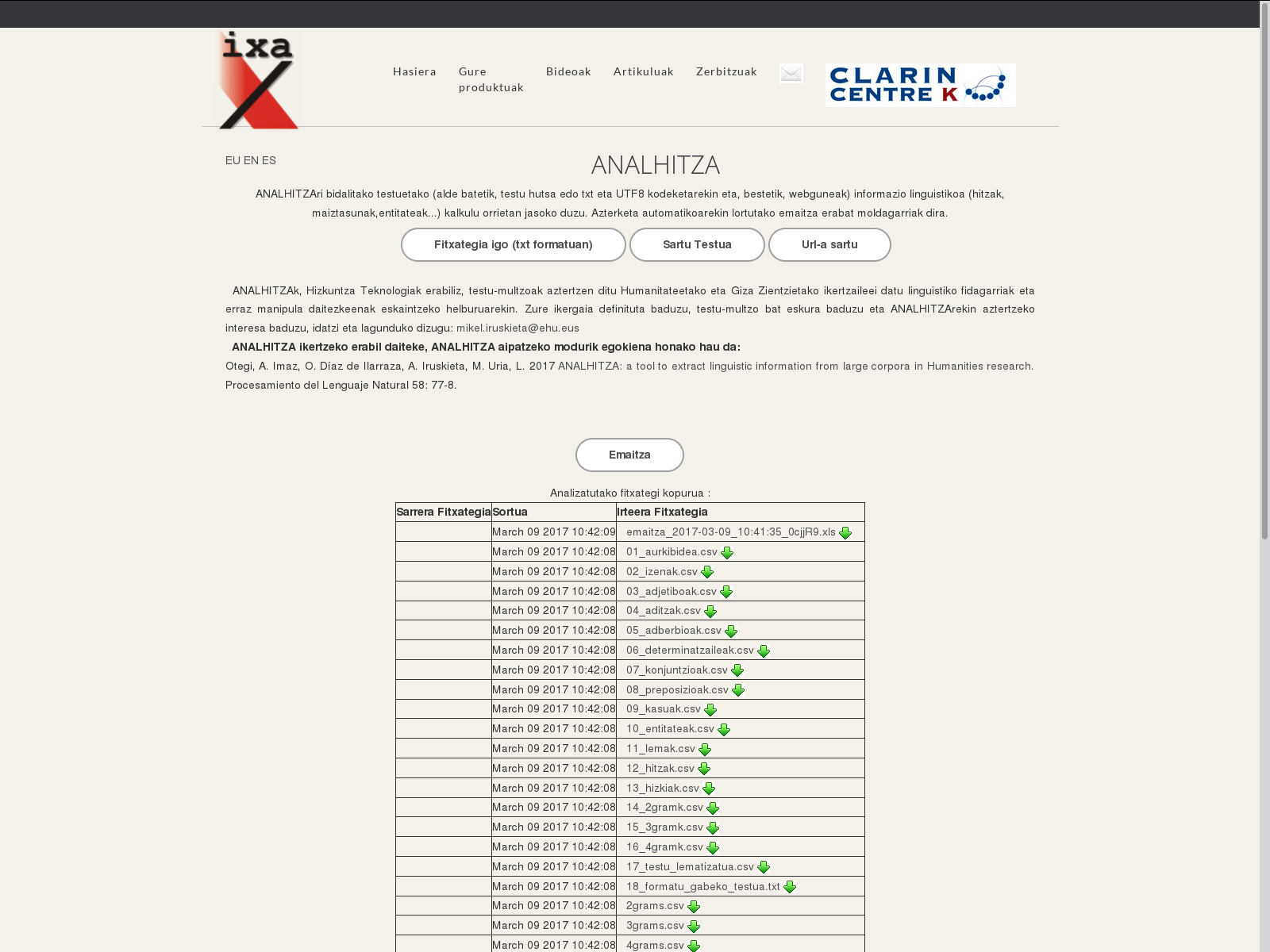
| EU | EN | ES |
ANALHITZA will help you extracting from text in Basque, Spanish or English, some linguistic information, such as:
- nouns, adjectives, verbs, adverbs...
- person names, location names...
- sequences of two, three and four words
- ... and much more!
The text could be the one that you have in a file, something that you will copy it here, or from a web page, but it should be encoded in UTF8. To use ANALHITZA, enter the text you want to analyze using one of the 3 below options, and then choose the language of your text (Basque, Spanish or English). After waiting a moment, you will get the results on an Excel file. Thus, you will be able to adapt the results to meet your requirements.

ANALHITZA processes automatically the text using ixaKat (for Basque) and Ixa pipes (for Spanish and English), which are two modular chains of linguistic processors.
ANALHITZA, making use of language technologies, has been designed with the purpose of offering to researchers from the fields of humanities and social sciences a simple way to obtain reliable and easily manipulable linguistic data. If you have defined a research topic in one of these fields, if you have a corpus and if you are interested in using ANALHITZA, contact us and we will advise you:
mikel.iruskieta@ehu.eus
You are free to use any information from this website, but we would appreciate an acknowledgement. The proper way to cite the ANALHITZA is the following:
Otegi, A. Imaz, O. Díaz de Ilarraza, A. Iruskieta, M. Uria, L. 2017 ANALHITZA: a tool to extract linguistic information from large corpora in Humanities research. Procesamiento del Lenguaje Natural 58: 77-84.